Of course. So if you made the following change to the code snippet
/*Comment out this whole block that creates edges personList = SELECT p FROM personList:p WHERE p.@newContact == TRUE POST-ACCUM FOREACH contact IN p.@newContactList DO INSERT INTO Has_contacted (FROM, TO) VALUES( p, contact ) END; */ /*Instead simply add the following*/ PRINT personList;
With that “PRINT” statement I’m able to see what changes would be made without making them. The response can be voluminous , so it’s always best to use “LIMIT”. I mainly use “PRINT” to help me make sure I’m getting the results I’m expecting. If you just add the print statement at the end and keep the code the same then you can see the changes that were made for each run. So with the schema we have defined
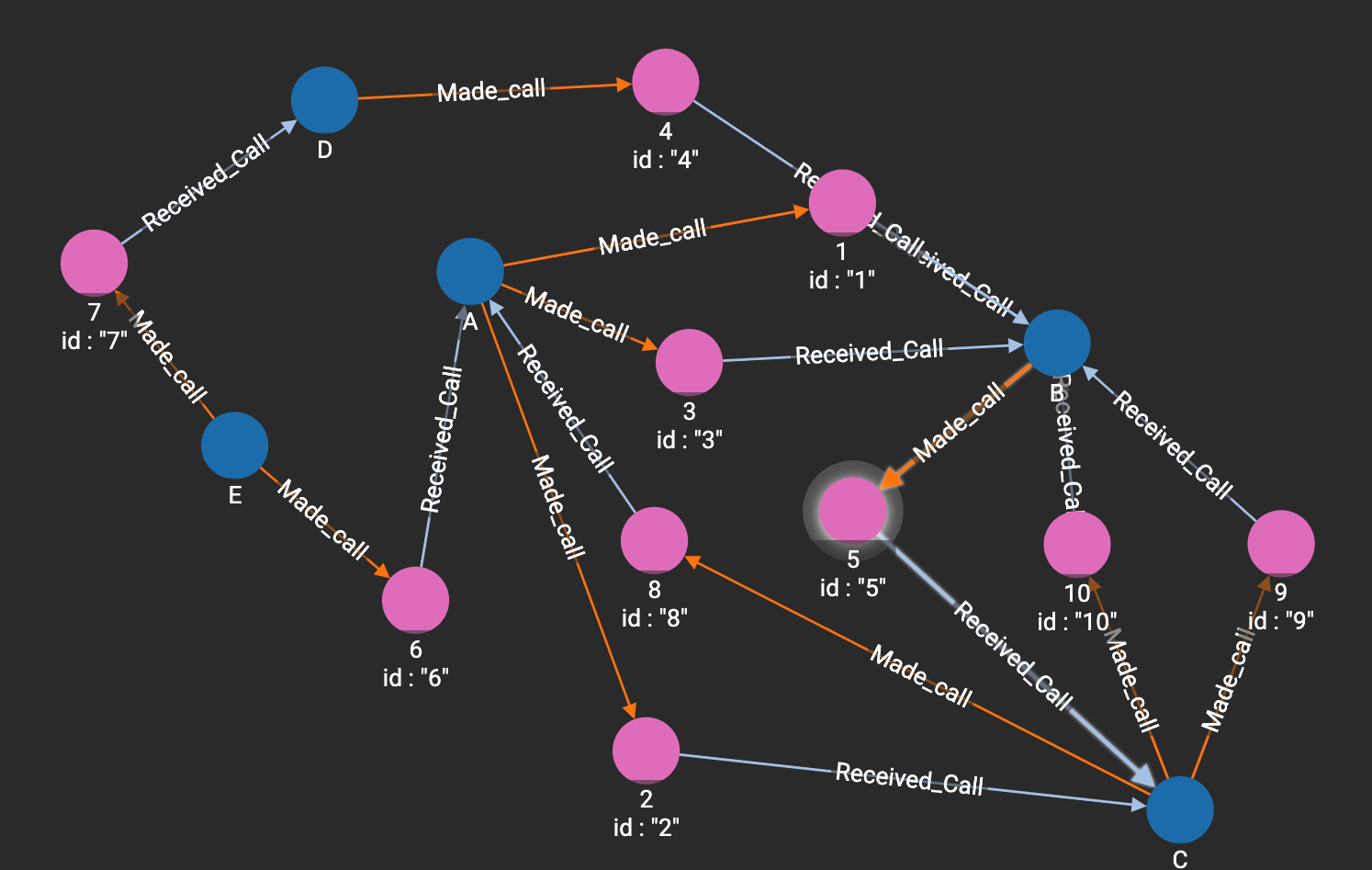
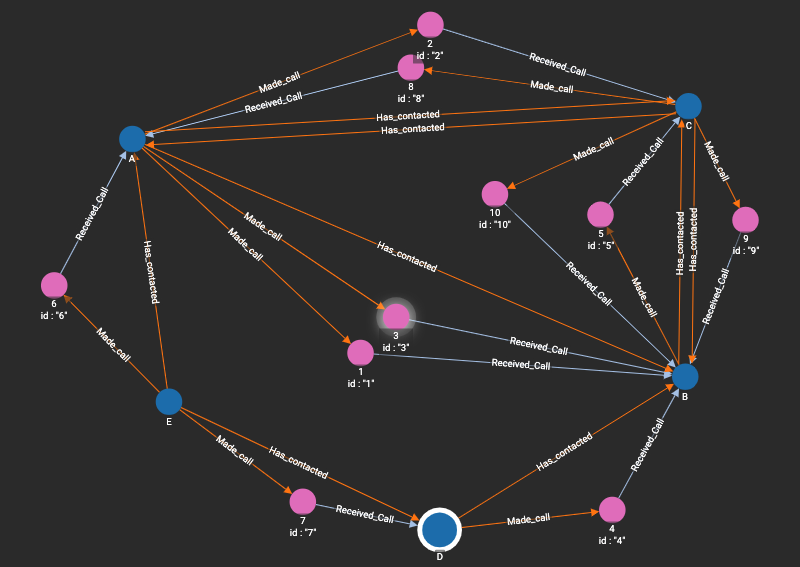
And the following simple data set I created
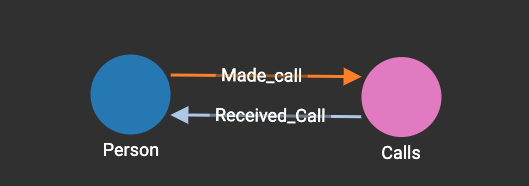
Where blue vertices are Persons and pink vertices are calls. If run the original query and add that PRINT statement I get the following JSON response
[
{
"personList": [
{
"v_id": "B",
"v_type": "Person",
"attributes": {
"PhoneNumber": "",
"@newContact": true,
"@contactList": [],
"@newContactList": [
"C"
]
}
},
{
"v_id": "A",
"v_type": "Person",
"attributes": {
"PhoneNumber": "",
"@newContact": true,
"@contactList": [],
"@newContactList": [
"B",
"C"
]
}
},
{
"v_id": "C",
"v_type": "Person",
"attributes": {
"PhoneNumber": "",
"@newContact": true,
"@contactList": [],
"@newContactList": [
"B",
"A"
]
}
},
{
"v_id": "D",
"v_type": "Person",
"attributes": {
"PhoneNumber": "",
"@newContact": true,
"@contactList": [],
"@newContactList": [
"B"
]
}
},
{
"v_id": "E",
"v_type": "Person",
"attributes": {
"PhoneNumber": "",
"@newContact": true,
"@contactList": [],
"@newContactList": [
"D",
"A"
]
}
}
]
}
]
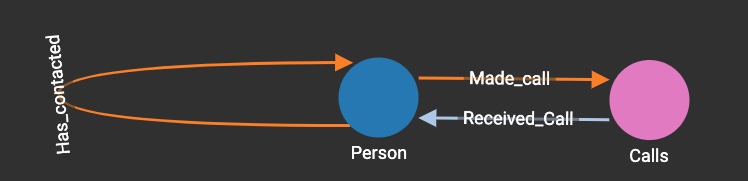
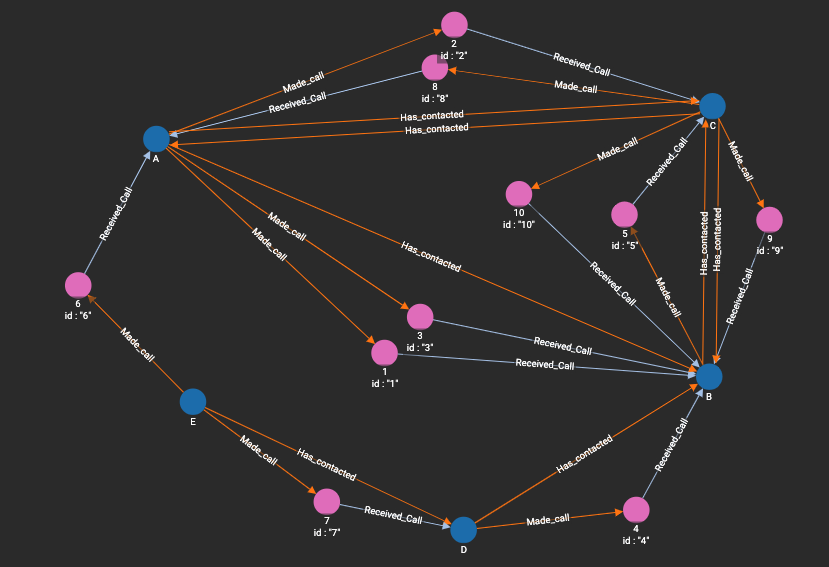
And my graph would now look like the following
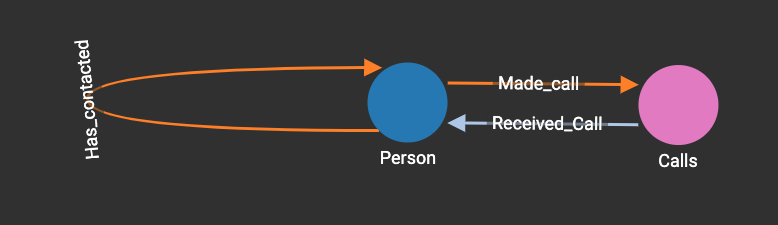
If we remove an edge, say the one between Person E and Person A
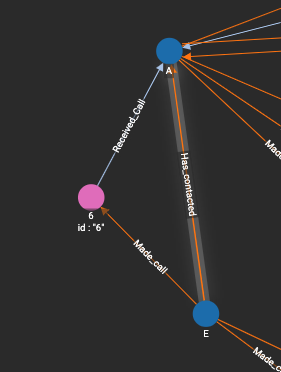
And we rerun the same query, our response is now just
[
{
"personList": [
{
"v_id": "E",
"v_type": "Person",
"attributes": {
"PhoneNumber": "",
"@newContact": true,
"@contactList": [
"D"
],
"@newContactList": [
"A"
]
}
}
]
}
]