
I created individual username/password for each user who are using my TG installation. There are situations where multiple users will need to run the same sets of scripts (creating the same graph, installing the same script, etc). Since everything is in the global scope, this flow doesn’t work at all. What are the recommendations for what I am trying to achieve other than having each user using their own TG installation? Thanks!
I’m not fully understanding your scenario. I’ll lay out some basic concepts and capabilities, and then maybe you can respond in those terms.
Almost nothing needs to exist at the global level in a TigerGraph MultiGraph system. In TigerGraph, a “graph” is a set of vertex types and edge types. Those types can be a mix of global types and local types; local types belong only to that graph.
A user identity is global, but most user privileges are with respect to one or more graphs. Queries and load jobs always belong to a particular graph; they are not global.
So, where does that leave us?
It sounds like you want a set of users who each have their own private spaces: multitenancy. MultiTenancy can be modeled well with MultiGraph.
It sounds like you want a set of standard scripts so that each user can create an identical (but separate) graph and have identical but separate queries. Is this correct?
You can do this, if you parameterize your scripts so that the name of each graph is different.
If you instead want users to share and work together in the same space, that of course is also supported.
1 Like
Thanks Victor!
Let’s say I have git repository with set of scripts that define schema (vertex, edge, etc), load the data, install queries, and run queries.
User A and B both clone the same repository. They both are granted role globaldesigner.
User A’s job is to collect benchmark data, which involves iterations of dropping everything he creates to have a clean start and then rebuilding the graph and running queries.
User B’s job is to improve the speed of certain queries but using the same set of scripts that A uses for testing.
Based on what you’re saying all I need is to for A and B to create the same graph under different name. However, base on my experiment, names of all vertices, edges, jobs, etc all need to be different. Below is the issue I am running into:
User A:
GSQL > ls
---- Global vertices, edges, and all graphs
Vertex Types:
Edge Types:
Graphs:
Jobs:
JSON API version: v2
Syntax version: v1
GSQL > create vertex immunizations(PRIMARY_ID Id String, PERFORMED_ON_DATE String, PATIENT String, CODE UINT)
The vertex type immunizations is created.
User B:
GSQL > create vertex immunizations(PRIMARY_ID Id String, PERFORMED_ON_DATE String, PATIENT String, CODE UINT)
Semantic Check Fails: The vertex name immunizations is used by another object! Please use a different name.
failed to create the vertex type immunizations
So if you can please send me some pointers on how to create local vertices, edges, tuples, etc, I will be able to take it from there.
As Victor wrote, you probably want to implement multi-tenancy. In this approach each graph would be disjunct, meaning there would not be vertex or edge types defined in the global scope, only within the graphs. Vertex and edge types created within a graph (local vertices and edges) are not visible outside, i.e. in the global scope and in other graphs. This means that two (or more) graphs can have exactly the same structure, but the object types and their instances are isolated. Thus people working in different graphs will not disturb others’ work.
There is one thing though that needs to be considered, although it’s not a big deal: the way you create object types in a graph is different from creating them in the global scope.
- In the global scope you use
CREATE VERTEXandCREATE [UN]DIRECTED EDGEstatements, thenCREATE GRAPHthat would include some or all of the global scope vertices and edges. - Within the a local graph, you first create an empty graph and then you use schema change job(s) in it that encapsulate vertex and edge creation statements.
The general workflow for you would look something like this:
CREATE GRAPH g1 ()
BEGIN
CREATE SCHEMA_CHANGE JOB scj1 FOR GRAPH g1 {
ADD VERTEX v1 (...);
ADD VERTEX v2 (...);
ADD EDGE e1 (...);
}
END
RUN SCHEMA_CHANGE JOB scj1
// You won't need the schema change job after it successfully run
DROP JOB scj1
This should probably implemented as a template with variables used instead of graph name, for easy reuse via some scripts.
1 Like
Thanks a lot ! This will make my flow a lot easier :). I’ll update my schema script to use multi-tenancy.
Regarding your comment “This should probably implemented as a template with variables used instead of graph name, for easy reuse via some scripts.”, since I haven’t found a way to pass a variable to gsql client, are you suggesting I do some file manipulation using a command like ‘sed’?
Yes, use sed/awk/Python, etc. to pick up the template, make the necessary substitutions and then pass the updated script/file to gsql command line client or via pyTigerGraph.
I think this can easily be incorporated into a workflow management solution, CD/CI system, IaaC/Puppet/Chef/you-name-it.
1 Like
Thanks @Szilard_Barany!
I will use sed, which is straightforward. I asked about it just in case I missed some option to pass variables to gsql script via gsql client, which would have been nice though :).
Would indeed be nice. Will put on the feature request list.
1 Like
@jimwu If you haven’t seen this video yet… I would highly suggest it!! In Optum we had 20+ developers working on multiple scripts across not only the same instance but other instances as well. This tool we developed was custom designed for that type of development.

2 Likes
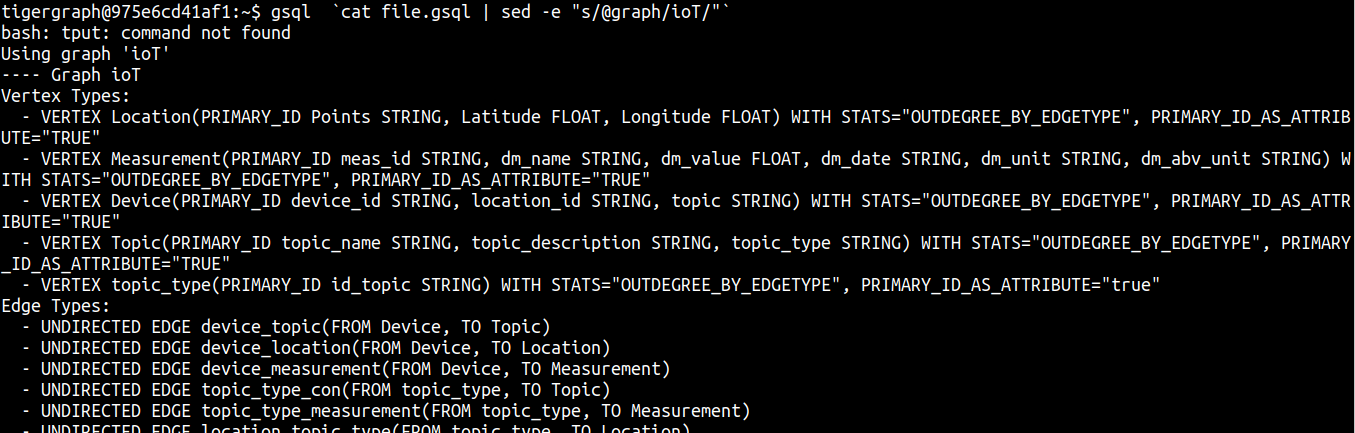
@jimwu you can use :
gsql -u tigergraph -p tigergraph `cat file.gsql | sed -e "s/@graph/ioT/"`
and use a file.gsql like this :
USE GRAPH @graph
LS
the output should be like this
1 Like
Thanks Jon! I will watch the video when I get a chance.
Just finished converting my scripts to use multi-graph. This is way way better and cleaner flow. Thanks to all who helped.
One last minor thing: is there a way to define graph specific tuple? I can’t find any documentation on this.